A one-stop-destination for data analytics, engineering and everything in between
A one-stop-destination for data analytics, engineering and everything in between
February 23, 2024 , In Data Visualization
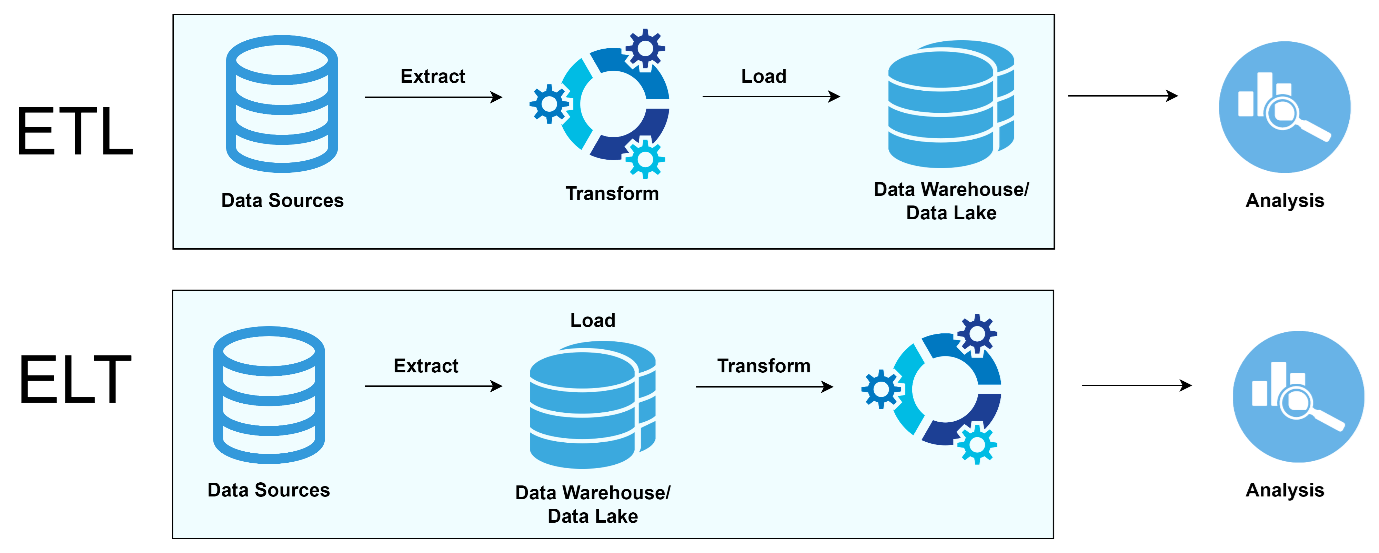
As modern data architecture evolves and becomes more powerful, the tools used to develop modern data architecture expand with varied capacities for tackling various challenges.
In this blog, we will discuss the benefits of adopting ELT over ETL, as well as three technologies that have a significant impact on current data architecture.
Understanding ELT
The fundamental data flow paradigm for big data and cloud analytics is represented by ELT, Extract, Load, and Transform. Instead of using an intermediary transformation layer like ETL, ELT collects raw data directly from sources and inserts it in to a data warehouse. Examples of this method that align with modern data architecture are cloud data warehouses such as AWS Redshift and Snowflake (1). The adaptability of ELT enables it to handle the expanding volumes of data related to big data solutions by storing raw data first and executing transformation afterwards. As data volumes increased, it became necessary to transition from ETL to ELT. Cloud-native warehouses built for columnar storage and parallel processing could now handle large datasets with efficiency (1).
Data Extraction using Fivetran.
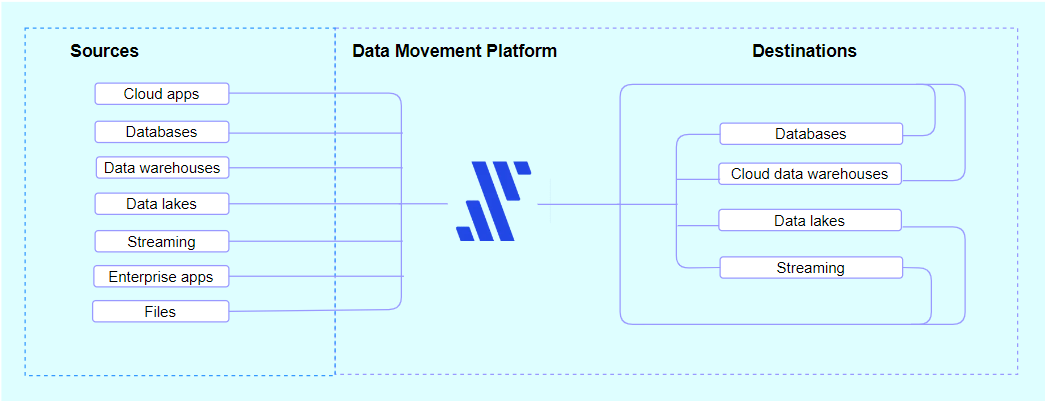
Fivetran is a Platform-as-a-Service that provides more than 200 built-in connectors for various sources, including databases, web applications, APIs, and ERP systems, eliminating the need for infrastructure administration (1). Fivetran makes connecting and centralizing data from several sources easier, saving time over more conventional approaches. It offers loading and extraction connectors and supports JDBC, ODBC, and other API methods (3). Pipelines for extraction might be scheduled periodically or sparked by fresh source data. Fivetran uses the database’s change capture mechanism to start an initial sync that transfers data from source to destination (3). New or modified data is then updated incrementally. It is also possible to set up re-syncs to update all data.
Data Loading in Snowflake.
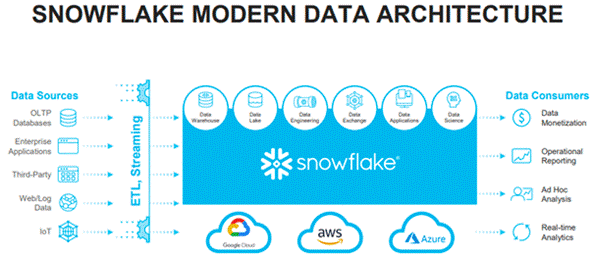
Utilizing cloud-based technology, Snowflake is a contemporary data warehouse that offers scalable resources, separate computing and storage, and a multi-clustered environment for best performance. Comparing this architecture to standard warehouses, cost and efficiency are increased. Features like columnar storage, parallel processing, and automatic query optimization are all part of Snowflake’s feature set (5). Spinning up an infinite number of virtual warehouses allows customers to run multiple independent workloads simultaneously and resize each warehouse in milliseconds. Peak performance is guaranteed throughout the day, and workload fluctuations are accommodated. The multi-cluster feature of Snowflake scales automatically, charging customers only while a cluster is in use. Snowflake is unique because it supports structured and semi-structured data formats, including Parquet, AVRO, and JSON (5).
Compared to historical warehouses, it provides a more affordable option for data lakes by separately scaling computation and storage. To combine their data lake, many users choose Snowflake since it makes it easy to integrate and analyze large amounts of data on a single platform (5). There is no longer a need for separate Data Lake and Data Warehouse systems because of the platform’s unique ability to query both structured and JSON data in an integrated way.
Data Transformations using DBT.
DBT complements the data warehouse phase by connecting to it, leveraging Snowflake’s SQL capabilities for data transformations. Utilizing Snowflake’s tables, DBT creates structured data models that are query-ready for analysis and reporting. It automates documentation generation, encompassing descriptions, model dependencies, SQL, sources, and tests. DBT’s Lineage graphs visualize data pipelines, offering insight into data relationships and business logic mapping (6). The platform includes built-in testing functions for uniqueness, non-null, referential integrity, and accepted values, with the flexibility to write custom tests using SQL. Applying tests to columns is seamlessly integrated into the YAML file used for documentation, simplifying data integrity verification. DBT’s compatibility with Git facilitates collaborative development and easy tracking of changes to data models and transformations (6).
Designed to work together.
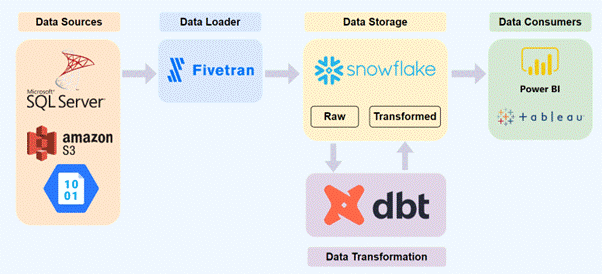
Fivetran offers continuous data replication and integration, connecting various sources with the Snowflake data cloud. This combination, complemented by dbt, helps convert raw data into analysis-ready data (4). The capabilities of Fivetran, Snowflake, and dbt deliver a best-in-class ELT pipeline. It ensures accelerated time to insight through centralized and transformed data, with simplified technology stack and pre-configured dbt data models, increased ROI by minimizing computational costs, and streamlined end-to-end ELT pipelines (4).
References:

Boston, Massachusetts
Chicago, Illinois

Mumbai, Maharashtra

 +1 978 330 6045
+1 978 330 6045