
Data Lakehouse Explained: Building a Modern and Scalable Data Architecture
Table of Contents
Introduction
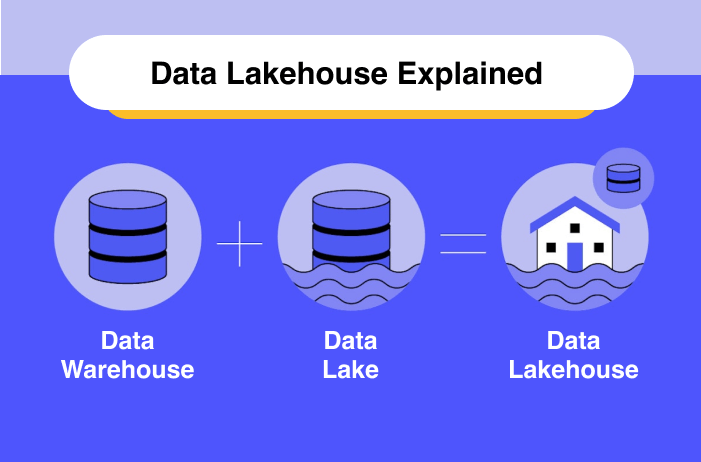
Data lakes are great for storing raw, large-scale data cheaply, but they have a weakness: no built-in support for transactions, consistency, or governance. As they grow, they risk turning into messy “data swamps.”
Delta Lake, created by Databricks, fixes these problems. It’s an open-source storage layer that adds ACID transactions, schema enforcement, and time travel on top of your existing data lake (S3, ADLS, HDFS). In short, Delta Lake combines the scalability of a lake with the reliability of a warehouse—a foundation for the modern “lakehouse” architecture.
What is a Data Lakehouse?
Difference Between Delta Lakes and Data Lakes?
Why Traditional Data Lakes Fall Short
- No transactions: Failed jobs leave partial or corrupted files.
- No schema control: Different pipelines may write incompatible structures.
- Concurrency issues: Parallel writes cause conflicts.
- Slow queries: File listing on large directories (e.g., S3) is inefficient.
These issues make pipelines fragile and analytics unreliable.
Delta Lake to the Rescue
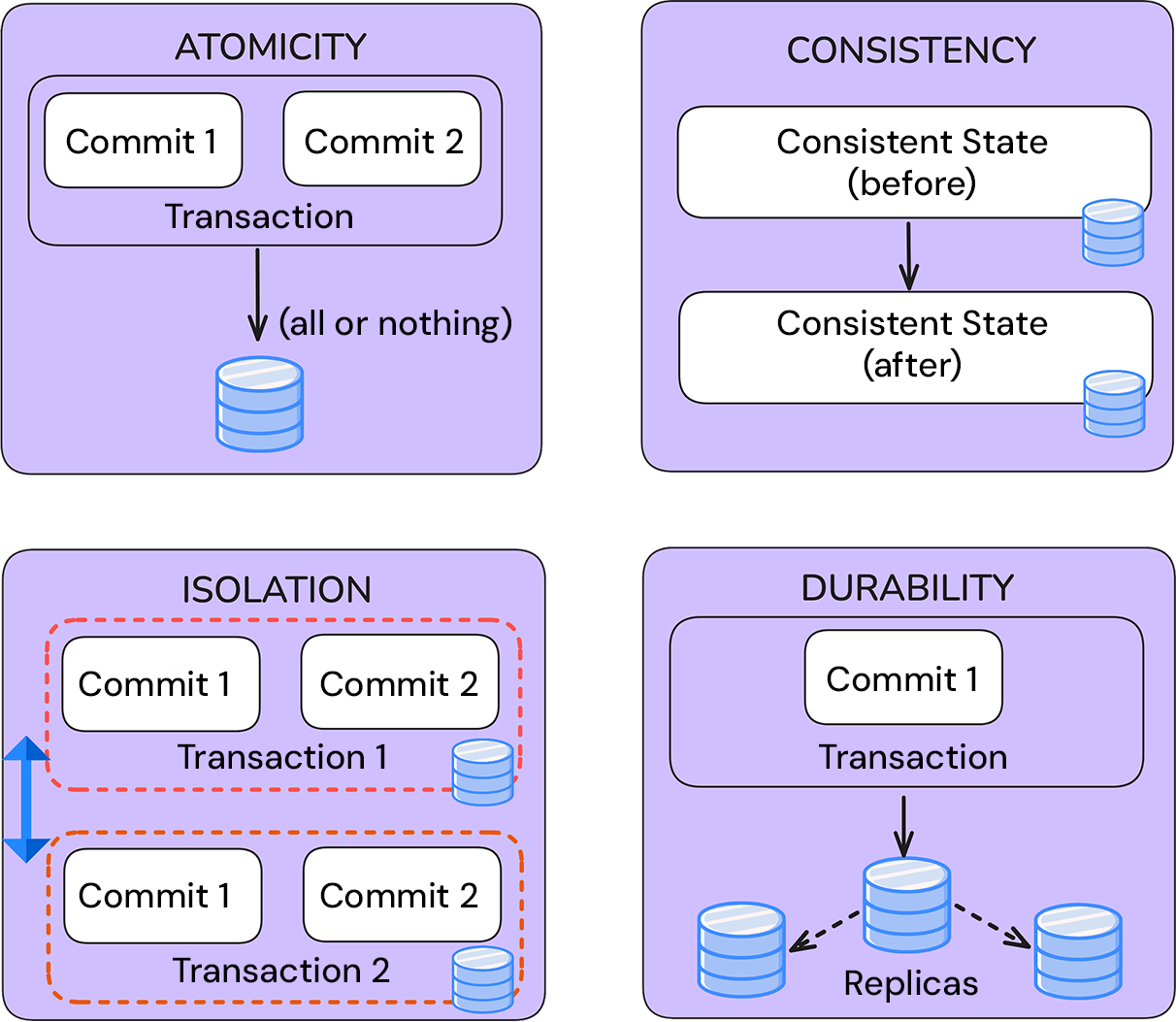
Delta Lake introduces a transaction log (_delta_log) that tracks every change. This enables:
- Atomicity: No half-written data if a job fails.
- Consistency: Schema rules enforced on every write.
- Isolation: Concurrent jobs don’t interfere.
- Durability: Once written, data persists.
Effectively, Delta turns data lakes into ACID-compliant systems.
Key Features
- Schema Enforcement & Evolution
Keeps data clean by rejecting invalid records and supports safe schema changes over time. - Time Travel & Versioning
Query previous table versions for rollback, audit, or reproducibility. - Unified Batch + Streaming
A single Delta table can serve both historical queries and real-time streams. - Performance Boosts
Faster queries with metadata indexing, file pruning, and optional clustering/compaction.
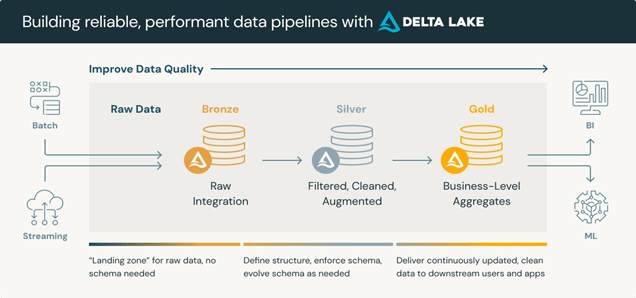
Delta Lake in Architecture
Delta Lake vs. Others
Alternatives like Apache Iceberg and Apache Hudi also bring ACID to lakes. But Delta Lake is widely adopted due to Spark integration, Databricks support, and ecosystem maturity—making it a leading choice for lakehouse architectures.
Conclusion
Delta Lake solves the reliability gap in traditional data lakes by making them transactional, consistent, and production ready. With schema enforcement, time travel, and unified batch/streaming, it enables teams to confidently build scalable pipelines and trust their data.
For organizations struggling with messy or unreliable lakes, adopting Delta Lake is a step toward a robust data lakehouse future.
Ready to Modernize Your Data Architecture? click here.
Contact OnPoint Insights today and learn how we can help you migrate from traditional data lakes to a robust data lakehouse architecture that combines scalability, governance, and performance. Our experts ensure a smooth transition so your teams can trust, query, and analyze data with confidence.
For more insights, explore the OnPoint Insights Blog where we share practical guides, migration tips, and expert viewpoints.
References




Collaborate with us
We're here to answer your questions and help you find the right solution.


"*" indicates required fields