
Introduction to Spark Performance Tuning
Table of Contents

Introduction
In the world of big data processing, Apache Spark has emerged as a powerhouse, allowing businesses to manage massive amounts of data with simplicity and efficiency. However, as the scale and complexity of Spark applications increase, so do the challenges involved with achieving peak performance. This is where performance tuning comes into play, as it is critical for enhancing Spark jobs’ speed, resource consumption, and scalability.
Why Performance Tuning Matters
Improving Spark application performance requires more than just reducing latency. It’s about maximizing the performance of your data processing pipelines, making the best use of your cluster’s resources, and, ultimately, providing results faster and more reliably.
Understanding the Spark Foundation
Before delving into the complexities of performance tweaking, it’s critical to understand the core concepts underlying Spark’s design and execution mechanism.
Spark runs on the distributed computing idea, processing data in parallel over a cluster of computers.
Spark’s execution architecture is built around concepts like Resilient Distributed Datasets (RDDs) and Directed Acyclic Graphs (DAGs), which serve as the foundation for Spark’s data processing flow.
Understanding Spark Execution Model
Spark’s exceptional performance stems from its execution architecture, which enables parallel execution of operations across dispersed datasets. Let’s take a closer look at some essential aspects:
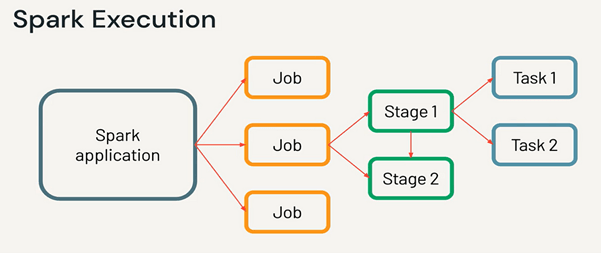
Stages, Tasks, and Transformations
Spark breaks computing into smaller, manageable chunks called stages and tasks. Stages are a collection of changes that can be run independently, whereas tasks are distinct units of work performed on each partition of data. Transformations, on the other hand, define the logic used to manipulate the data, such as map, filter, or reduce operations.
Parallel and Lazy Evaluation
Spark’s defining characteristic is its lazy evaluation strategy, which defers changes until an action is triggered. This enables Spark to optimize the execution plan and efficiently arrange tasks throughout the cluster, maximizing parallelism while minimizing overhead.
RDD and DAG
Resilient Distributed Datasets (RDDs) are the primary abstraction in Spark, representing immutable collections of data that can be processed concurrently across the cluster. RDDs serve as the foundation for generating Directed Acyclic Graphs (DAGs), which capture transformation dependencies and guide Spark job execution.
Identifying Performance Bottlenecks
Optimizing Data Partitioning
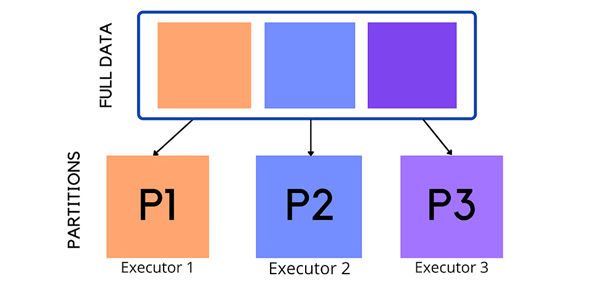
Parallelism and scalability in Spark applications rely on effective data partitioning. Spark can carry out tasks in parallel by distributing data over several partitions, maximizing the cluster’s capacity. Here’s how to optimize data splitting for better performance:
The importance of proper partitioning
Proper data partitioning maximizes parallelism while minimizing overhead. Partitioned data enables Spark to efficiently distribute compute and resources across the cluster, reducing hotspots and bottlenecks.
Effective partitioning algorithms can eliminate costly shuffles, improve performance, and minimize data migration.
Techniques for Partitioning Optimization
Techniques for Partitioning Optimization: Partitioning optimization techniques include
- balancing partition count based on data size,
- cluster setup,
- and workload factors to maximize resource use and parallelism.
Choosing the appropriate partitioning approach, such as hash or range partitioning, might affect data locality and job distribution.
Custom Partitioners: Tailoring partitioning algorithms to specific data patterns or key distributions improves efficiency and data localization.
Memory Management Strategies in Spark
Leveraging Caching and Persistence
Fine-tuning Spark Configurations
Utilizing Data Locality for Improved Performance:
Efficient Resource Management in Spark
Monitoring and Profiling Spark Applications:
Benchmarking and Testing Strategies:
Best Practices for Spark Performance Optimization
Conclusion
Ready to unlock the full potential of Apache Spark? click here.
Contact OnPoint Insights today and see how we can help you fine-tune Spark performance for faster data processing, better scalability, and improved efficiency. +1(978) 788 2563
For more insights, explore the OnPoint Insights Blog, where we share practical tips on analytics, BI, data strategy, AI & ML, and more.
References




Collaborate with us
We're here to answer your questions and help you find the right solution.


"*" indicates required fields