
Leveraging Snowflake and Snowpark for Seamless API Data Ingestion
Table of Contents

Introduction
In today’s data-driven world, businesses increasingly rely on external APIs to enrich their analytical insights. From financial market data to social media feeds and IoT sensor data, APIs are a treasure trove of information. However, ingesting diverse and dynamic data into a data warehouse efficiently and reliably can be challenging.
Traditionally, integrating API data into a data warehouse like Snowflake often involves building complex ETL (Extract, Transform, Load) pipelines outside the platform. This usually meant managing external compute resources, handling data transformations in separate scripts, and dealing with the overhead of data movement. This approach could lead to increased operational complexity, higher costs, and potential data latency.
Enter Snowflake and Snowpark. This powerful combination offers a paradigm shift, allowing organizations to bring computation to the data, rather than the other way around. With Snowpark, developers can leverage familiar programming languages like Python to build robust data pipelines directly within Snowflake, streamlining API data ingestion like never before.
The Challenges of API Data Ingestion
Before diving into the solution, let’s briefly review the common hurdles faced when integrating API data:
- Diverse API Structures: APIs come in various formats (REST, SOAP, GraphQL) and often return data in nested JSON, XML, or other complex structures, requiring intricate parsing and flattening.
- Authentication and Authorization: Securely managing API keys, tokens, and OAuth flows can be tedious and time-taking.
- Rate Limiting and Paginating: APIs may impose restrictions on the number of requests per unit of time, necessitating careful handling of rate limits and pagination to retrieve complete datasets.
- Error Handling and Retries: Network issues, API downtime, or malformed responses require robust error handling and retry mechanisms to ensure data integrity.
- Scalability: As both the volume of data and how frequently it’s collected increase, the pipeline must scale efficiently to avoid performance or cost issues.
- Data Transformation: Raw API data often needs significant transformation, cleansing, and enrichment before it’s ready for analysis.
Why Snowflake and Snowpark Are a Game-Changer
A Practical Approach to API Data Ingestion with Snowpark
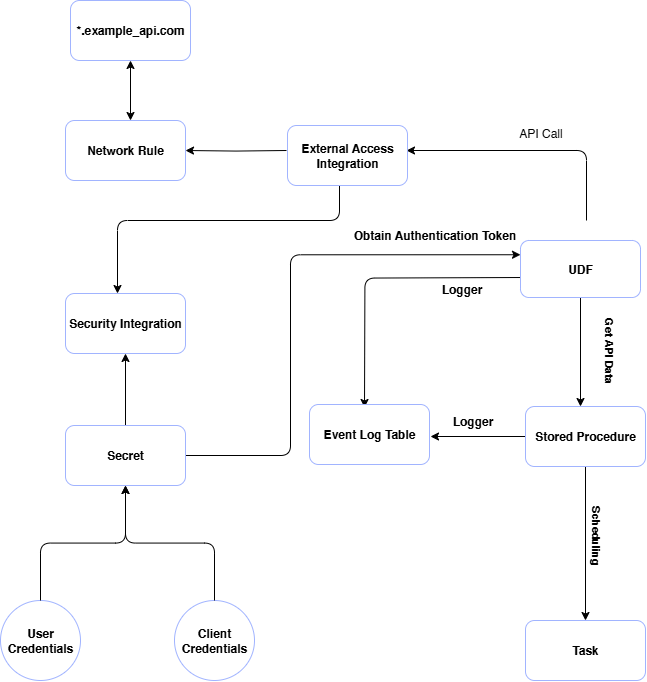
Best Practices for Optimal API Data Ingestion
- Incremental Loads: For large and frequently updated APIs, implement incremental loading strategies to fetch only new or changed data, minimizing processing time and costs.
- Data Validation: Incorporate data validation checks within your Snowpark code to ensure the ingested data meets quality standards before it’s loaded into the final tables.
- Schema Evolution: Be prepared for potential changes in API response schemas. Snowflake’s schema evolution capabilities and careful schema inference in Snowpark can help manage this.
- Monitoring and Alerting: Leverage Snowflake’s monitoring tools (e.g., Query History, Account Usage views) and integrate with external alerting systems to track the health and performance of ingestion pipelines.
- Modular Code: Break down complex ingestion logic into smaller, reusable Snowpark functions and procedures.
- Parameterized Queries: Use parameters for API URLs, table names, and other dynamic values to make the ingestion process flexible and reusable.
Conclusion
Leveraging Snowflake and Snowpark for API data ingestion empowers data professionals to build highly efficient, scalable, and secure data pipelines directly within the data cloud. By embracing the “code-to-data” paradigm, organizations can significantly reduce complexity, optimize costs, and accelerate the time to insight from valuable external API sources. As the demand for real-time and diverse data continues to grow, Snowpark will undoubtedly play a pivotal role in shaping the future of data integration.
To explore how we can help your business streamline API data ingestion with Snowflake and Snowpark click here.
Contact OnPoint Insights today and see how we can help your business operations reporting needs!
+1 (978) 788 2563
For more insights, explore the OnPoint Insights Blog, where we share practical tips on analytics, BI, data strategy, AI & ML, and more.
References



Collaborate with us
We're here to answer your questions and help you find the right solution.


"*" indicates required fields