Introduction
In modern industrial operations, machines, sensors, and HMI (Human-Machine Interface) systems generate massive volumes of data continuously. Efficiently processing and analyzing this data is critical for operational efficiency, predictive maintenance, and informed decision-making.
When designing data pipelines, engineers face a choice between real-time (streaming) processing and batch processing. Each approach has its advantages, challenges, and ideal use cases. This blog explores both approaches and guides you on when to use each.
Batch Processing
Batch processing involves collecting data over a period and processing it as a single batch at scheduled intervals, such as hourly, daily, or weekly.
Key Characteristics
- Processes data after collection.
- Suitable for large volumes of historical data.
- Commonly used in traditional ETL pipelines.
- Executes at fixed intervals using schedulers (e.g., cron jobs, Airflow).
- Typically runs on distributed systems such as Hadoop, Spark, or Databricks.
- Optimized for throughput rather than latency.
- Easier to perform aggregations, joins, and complex transformations.
Advantages
- Simplicity: Easier to implement and maintain.
- Efficiency: Can handle large datasets in bulk.
- Consistency: Processes a complete snapshot of data.
- Resource Management: Compute resources are used periodically rather than continuously.
- Cost-Effective: Since it runs periodically, it’s often cheaper for large-scale analytics.
- Reliable and Repeatable: Ideal for reprocessing data or generating reports with consistent results.
- Integration Friendly: Works well with data warehouses and BI tools for reporting and dashboards.
Disadvantages
- Latency: Insights are delayed until the batch is processed.
- Not Ideal for Immediate Alerts: Cannot respond to events in real time.
- Potential Data Staleness: Time-sensitive decisions may rely on outdated information.
- Higher Storage Needs: Intermediate batch files and checkpoints can consume large storage.
- Limited Interactivity: Not suited for dynamic dashboards or live analytics.

Real-Time (Streaming) Processing
Real-time processing analyses data as it is generated, often within milliseconds or seconds. This is crucial for HMI readings, sensor data, or IoT devices where immediate action may be required.
Key Characteristics
- Continuous processing of incoming data.
- Supports immediate alerts and automated actions.
- Often implemented using frameworks like Apache Kafka, Spark Structured Streaming, Flink, or AWS Kinesis.
- Handles event-by-event or micro-batch processing.
- Enables low-latency analytics and real-time dashboards.
- Integrates seamlessly with IoT devices, SCADA systems, and machine telemetry.
- Requires robust fault-tolerance and event ordering mechanisms.
Advantages
- Immediate Insights: Detect anomalies or equipment failures instantly.
- Better Operational Decisions: Supports monitoring and predictive maintenance.
- Event-Driven Analytics: Triggers actions automatically based on thresholds.
- High Responsiveness: Enables instant reactions in industrial control systems.
- Improved Safety and Efficiency: Prevents machine failures or safety hazards through instant alerts.
- Enhanced Customer Experience: Useful for systems needing immediate feedback loops.
- Scalable and Flexible: Modern streaming tools can scale horizontally to process millions of events per second.
Disadvantages
- Complexity: Implementation and maintenance are more challenging.
- Resource Intensive: Requires continuous compute and storage resources.
- Error Handling: Late-arriving or duplicate events need careful management.
- Higher Cost: Always-on processing can increase infrastructure costs.
- Data Ordering Challenges: Managing out-of-sequence data can be tricky.
- Debugging Difficulty: Continuous data flow makes testing and debugging harder.
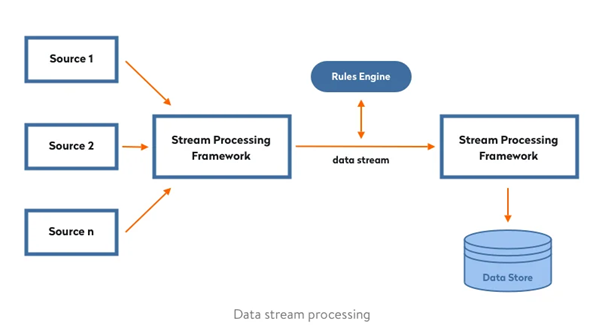
Hybrid Approach
Many organizations use a hybrid approach (sometimes called Lambda Architecture), combining batch and streaming layers:
- Batch layer: Processes historical and aggregated data.
- Streaming layer: Provides low-latency, real-time insights.
This approach ensures timely insights without sacrificing efficiency, providing both historical trends and immediate alerts.

Choosing the Right Approach
- Use batch processing for historical trend analysis, reporting, or data aggregation where latency is acceptable.
- Use real-time processing for immediate alerts, monitoring, and operational decision-making.
- Combine both approaches when your system requires both historical and real-time insights.
Best Practices for Production Data Pipelines
- Understand Your Requirements: Identify which metrics need real-time insights versus historical analysis.
- Select the Right Tools: Use Spark Structured Streaming, Kafka, Flink, or Delta Lake for industrial data pipelines.
- Ensure Data Quality: Handle missing, duplicate, or delayed sensor readings carefully.
- Monitor Resource Usage: Real-time pipelines can be resource-intensive; plan infrastructure accordingly.
- Combine Approaches When Needed: Not every use case requires real-time processing; batch and streaming can complement each other effectively.
Conclusion
Both batch and real-time processing play important roles in production data pipelines. Batch processing is ideal for efficiency, historical analysis, and reporting, while real-time processing enables immediate alerts, monitoring, and operational decision-making. By understanding your operational needs and applying the right approach, or combining both, you can ensure accurate, timely, and actionable insights from production data.
Ready to Optimize Your Production Data Pipelines? click here.
Contact OnPoint Insights today to discover how we can help you design and implement scalable, efficient, and intelligent data pipelines for your production environment. Whether you’re aiming for real-time monitoring, predictive maintenance, or large-scale batch analytics, our experts ensure your data works seamlessly to drive operational excellence.
For more insights, explore the OnPoint Insights Blog, where we share practical strategies, architecture comparisons, and proven methods for building modern, high-performing data systems.
References:
- Yalantis, Real-Time Big Data Processing
- GeeksforGeeks, Lambda Architecture
- Estuary, Data Streaming Architecture