Introduction
In today’s data-driven world, organizations must capture, process, and analyze massive amounts of data while maintaining flexibility, scalability, and governance. Microsoft Fabric provides a unified platform that simplifies how data is managed, integrated, and transformed across the enterprise.
Traditional data pipelines built on rigid, hardcoded logic struggle to keep up with modern demands—changing schemas, diverse data sources, and the need for real-time insights. To address these challenges, we designed a metadata-driven pipeline in Microsoft Fabric, where execution is controlled by metadata stored in configuration tables instead of embedded code.
By defining what to process, how to transform it, and where to store it through metadata, this approach enables pipelines to adapt dynamically, scale efficiently, and provide end-to-end transparency. This blog explores how a Microsoft Fabric metadata-driven pipeline was implemented using the medallion architecture (Bronze, Silver, Gold), with each layer governed by its own configuration.
Why Build Metadata-Driven Pipelines in Microsoft Fabric?
A metadata-driven pipeline replaces static, hardcoded logic with dynamic, metadata-based control. At runtime, the pipeline queries configuration tables to determine its actions.
In Microsoft Fabric, this approach delivers several key advantages:
- Flexibility – Easily add or modify data sources by updating configuration tables instead of pipeline code.
- Reusability – Shared logic works seamlessly across multiple datasets.
- Governance – Metadata provides a clear, auditable record of ingestion and transformation rules.
- Scalability – New sources and rules can be introduced without additional development effort.
By building around metadata within Microsoft Fabric, data pipelines become smarter, more agile, and easier to maintain over time.
Medallion Architecture in Microsoft Fabric
The pipeline was designed around the Medallion Architecture—Bronze, Silver, and Gold layers—implemented using Microsoft Fabric Lakehouse and its orchestration capabilities. Metadata drives execution at every stage, ensuring consistency and flexibility.
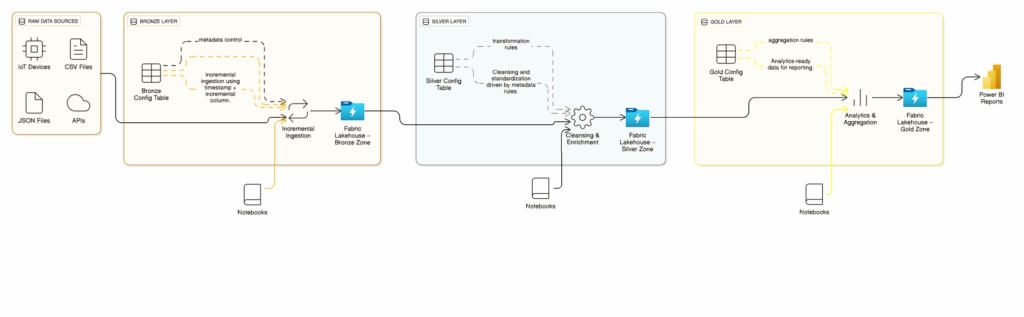
Bronze Layer: Incremental Ingestion
The Bronze layer handles raw data ingestion into the Fabric Lakehouse. To efficiently process large volumes, ingestion was designed to be incremental and fully guided by metadata.
The Bronze Config Table stores:
- Source file locations and schema definitions
- File formats and ingestion rules (CSV, JSON, Parquet, etc.)
- Two columns for incremental loading:
- Timestamp Column – Tracks the latest processed timestamp
- Incremental Column – Identifies which field (e.g., created_at or updated_on) drives incremental logic
With this design, the Bronze layer only ingests new rows since the last run, ensuring fast and efficient processing within Microsoft Fabric.
Silver Layer: Cleansing and Transformation
The Silver layer applies cleansing, normalization, and enrichment to Bronze data, making it analytics-ready. Its Silver Config Table defines:
- Which transformation notebooks or scripts to execute
- Column mappings and data standardization rules
- Business logic (such as unit conversions and reference lookups)
- Incremental update columns for optimized refreshes
Centralizing transformation rules in metadata makes Silver processing highly adaptable within Microsoft Fabric. Adding a new data rule or mapping requires only a configuration update—no code changes needed.
Gold Layer: Aggregations and Analytics
The Gold layer produces refined, analytics-ready datasets often consumed directly in Power BI through Microsoft Fabric. Its Gold Config Table defines:
- Aggregation and calculation logic (KPIs, metrics, rollups)
- Target table names and reporting schemas
- Relationships between Silver outputs and analytical models
This metadata-driven approach ensures consistent, transparent analytics that can evolve with business needs—all within Microsoft Fabric’s integrated environment.
Metadata-Driven Orchestration in Microsoft Fabric
Unlike traditional pipelines, orchestration in Microsoft Fabric is dynamically driven by metadata. Execution flows are determined at runtime based on the configuration of each layer:
- The Bronze config defines what raw data to ingest and how incremental progress is tracked.
- The Silver config identifies transformation rules and dependencies.
- The Gold config specifies reporting outputs and analytical relationships.
Each layer runs independently based on metadata, creating a modular and resilient system. New datasets can be added by simply inserting a row into the corresponding configuration table—no pipeline modifications required.
This enables a self-orchestrating pipeline in Microsoft Fabric, where metadata controls logic, order, and execution across the entire data lifecycle.
Real-World Use Case: IoT Data in Microsoft Fabric
This metadata-driven design was implemented to process large-scale IoT data streams within Microsoft Fabric. Each run needed to efficiently capture only new sensor data without reprocessing historical records.
The Bronze config managed this by storing timestamps and incremental columns:
- The IoT table used event_time as its incremental column.
- The config table tracked the maximum ingested timestamp.
- On each new run, only rows with newer event_time values were loaded.
Once ingestion completed, the Silver layer standardized data formats, enriched records using reference datasets, and handled schema drift—all defined through metadata.
Finally, the Gold layer aggregated the cleansed data into KPIs and dashboards directly accessible through Power BI in Microsoft Fabric.
This end-to-end automation, powered entirely by metadata, minimized manual intervention and maintained high data freshness.
Key Benefits of Metadata-Driven Pipelines in Microsoft Fabric
- Incremental Efficiency – Timestamp-based ingestion ensures only new data is processed.
- Layer-Specific Configurations – Separate Bronze, Silver, and Gold config tables improve modularity and clarity.
- Scalability – New data sources are onboarded through metadata updates, not code.
- Maintainability – Config tables enhance governance, making pipelines transparent and auditable.
- Seamless Integration – Gold outputs connect directly to Power BI through Microsoft Fabric, keeping analytics up to date.
Challenges Solved with Microsoft Fabric
Several challenges were successfully addressed through the Microsoft Fabric metadata-driven approach:
- Schema evolution – Config-driven mappings simplified adjustments when schemas changed.
- High-volume ingestion – Incremental design ensured efficient ingestion as data scaled.
- Complex transformations – Centralized business rules reduced duplication and maintenance overhead.
- Governance – Configuration tables provided full visibility into transformation logic and lineage.
Lessons Learned
Building this Microsoft Fabric metadata-driven pipeline revealed key takeaways:
- Incremental logic is essential – Timestamp and incremental columns avoided full reloads.
- Modular configs improve clarity – Layer-specific configuration tables simplified design.
- Metadata must evolve – Config schemas should remain flexible to support future growth.
- Fabric’s unified environment accelerates delivery – Integration of Lakehouse, Pipelines, and Power BI shortened development cycles.
Conclusion
Metadata-driven pipelines represent a major shift in data engineering. By externalizing orchestration and logic into configuration tables, pipelines become adaptive, scalable, and easy to manage.
In this Microsoft Fabric implementation, the Bronze layer handled incremental ingestion efficiently, while the Silver and Gold layers applied transformation and analytics logic defined entirely by metadata.
The result was a system that:
- Processes IoT data incrementally within Microsoft Fabric
- Scales easily with new data sources
- Maintains transparency through metadata governance
- Delivers real-time insights directly into Power BI
For any organization adopting Microsoft Fabric, metadata-driven pipelines are not just an enhancement—they are the foundation for resilient, future-ready, and intelligent data systems.
Ready to Build Smarter Data Pipelines in Microsoft Fabric? click here.
Contact OnPoint Insights today to discover how we can help you design and implement metadata-driven pipelines in Microsoft Fabric that are scalable, efficient, and built for the future. Whether your goal is real-time analytics, governed data integration, or modernizing existing architectures, our experts ensure your data flows intelligently across every layer.
For more insights, explore the OnPoint Insights Blog, where we share practical strategies, architecture comparisons, and proven methods for building modern, high-performing data systems.
References: